Java web application containers allow distributed sessions by default. The only things you have to do is:
- Setting up your cluster (config)
- Having a Load-Balancer
- Adding
<distributable />into your web.xml - And having all your models implement Serializable
This allows you to run your web application on a Tomcat, JBoss or Jetty cluster. As soon as users start sessions, the whole session is replicated after the request among the other servers. This means, all the session data is always available to the other nodes. This can be good and bad. Because there is no session persistence, this can be good - there is no database or datastore. This is also bad. The cluster communication overhead grows with every server and every session. In addition to that, a huge session needs bandwidth and time for serialization and deserialization. And that is a bottleneck which can cause your cluster freeze.
I'd like to propose a slightly different approach. In contrast of maintaining a global shared state on all machines I'd like to maintain the state on only the affected machines (by user requests) and hold the session persistent. Only machines, which will get requests for the session will hold the session data. This is 1/N of a cluster of N nodes.
So let's take a more detailed look:
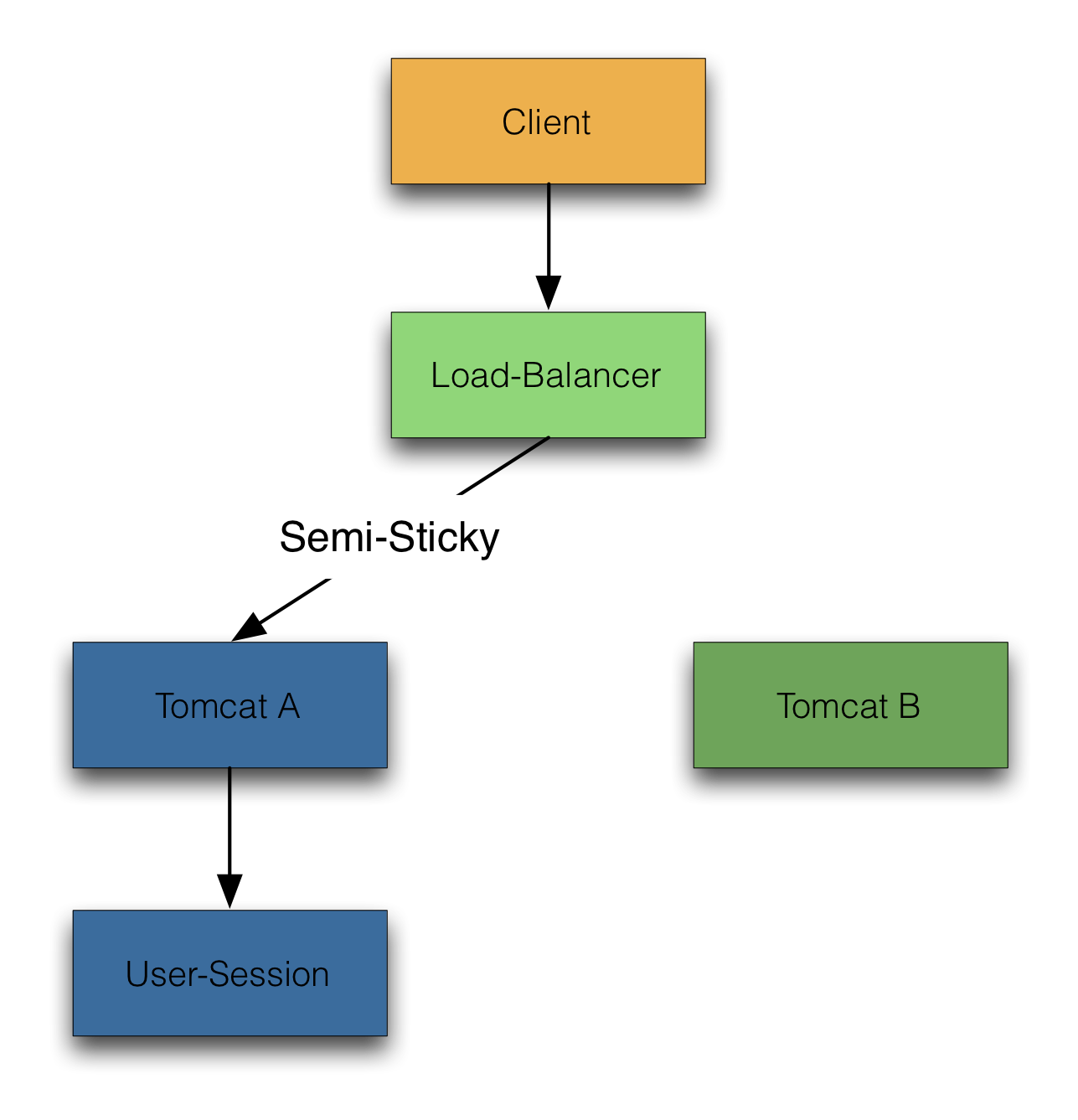
The first request to a web-app with a session creates the session and produces therefore a state. Without replication (sticky session) the session is maintained only on one node.
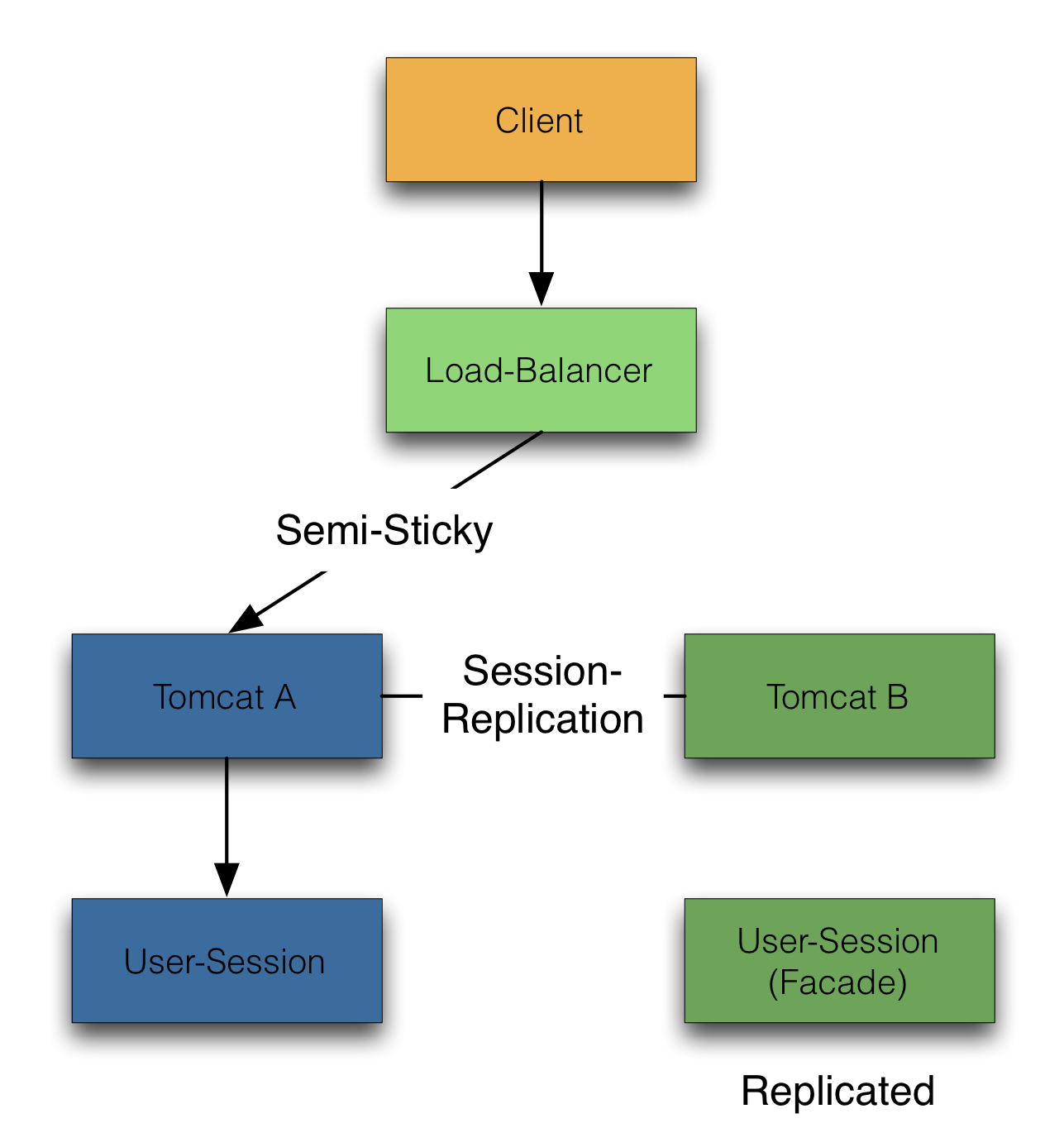
As soon as the server dies, the session is lost and the user will see it.
With replication, the session of the used application server is replicated to all nodes in the cluster. As soon as a server dies, the failover is transparent to the user. But all the session data is held by all nodes in the cluster. The more sessions you have with the more memory it consumes globally - until the servers quit with OutOfMemoryError.
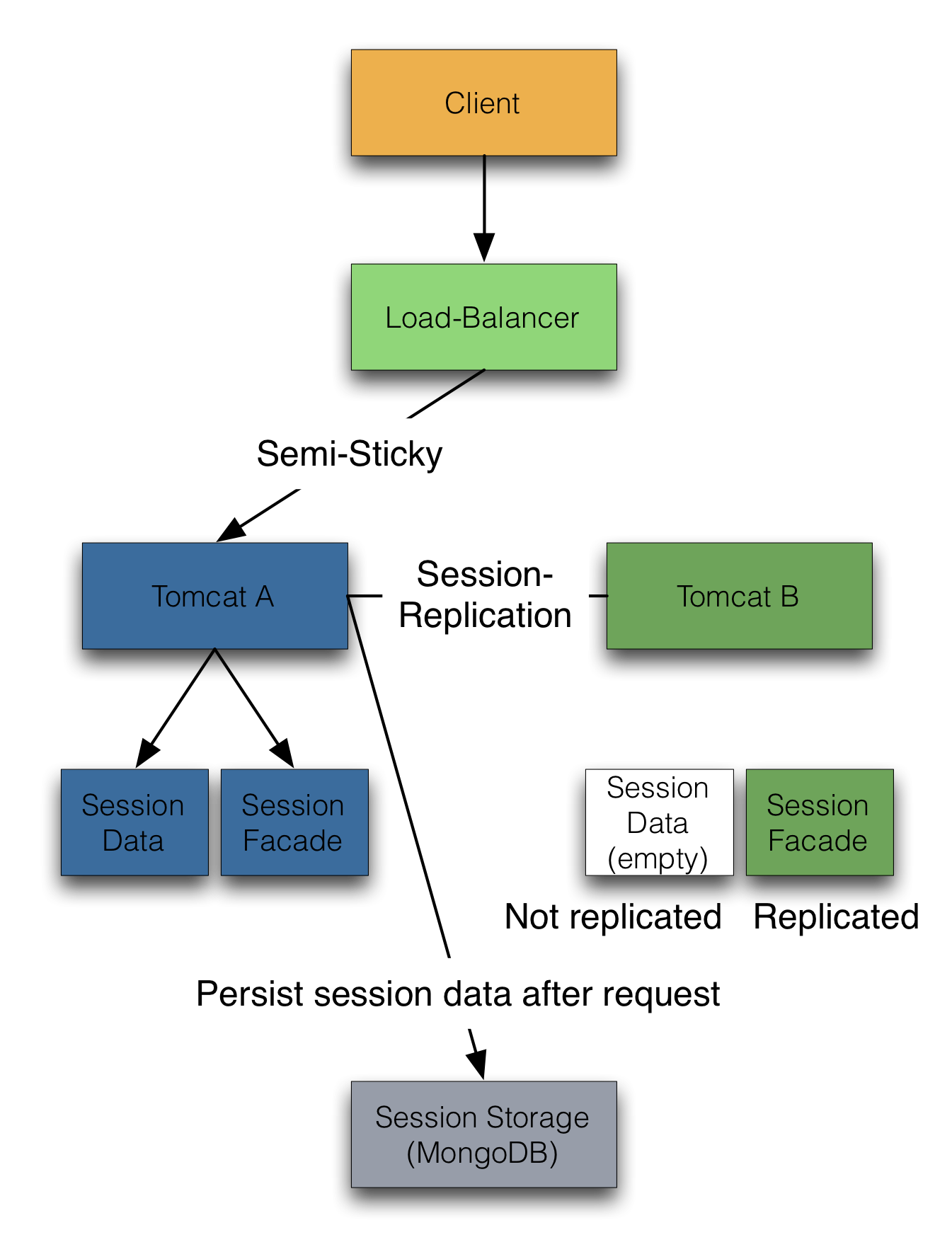
Now let's look at the lightweight session facade pattern. In this scenario we have still a session on one tomcat which is replicated. But that session is split in a replicated partition and a not replicated part: The session facade and the session data. The session facade is holding a global (replicated) session timestamp and a local (not replicated) session timestamp. This will get important in the failover scenario. But for now, after every user request the session data is persisted into a session data store (async, MongoDB in my example). All nodes in the cluster will receive only a tiny session facade containing the global session timestamp.
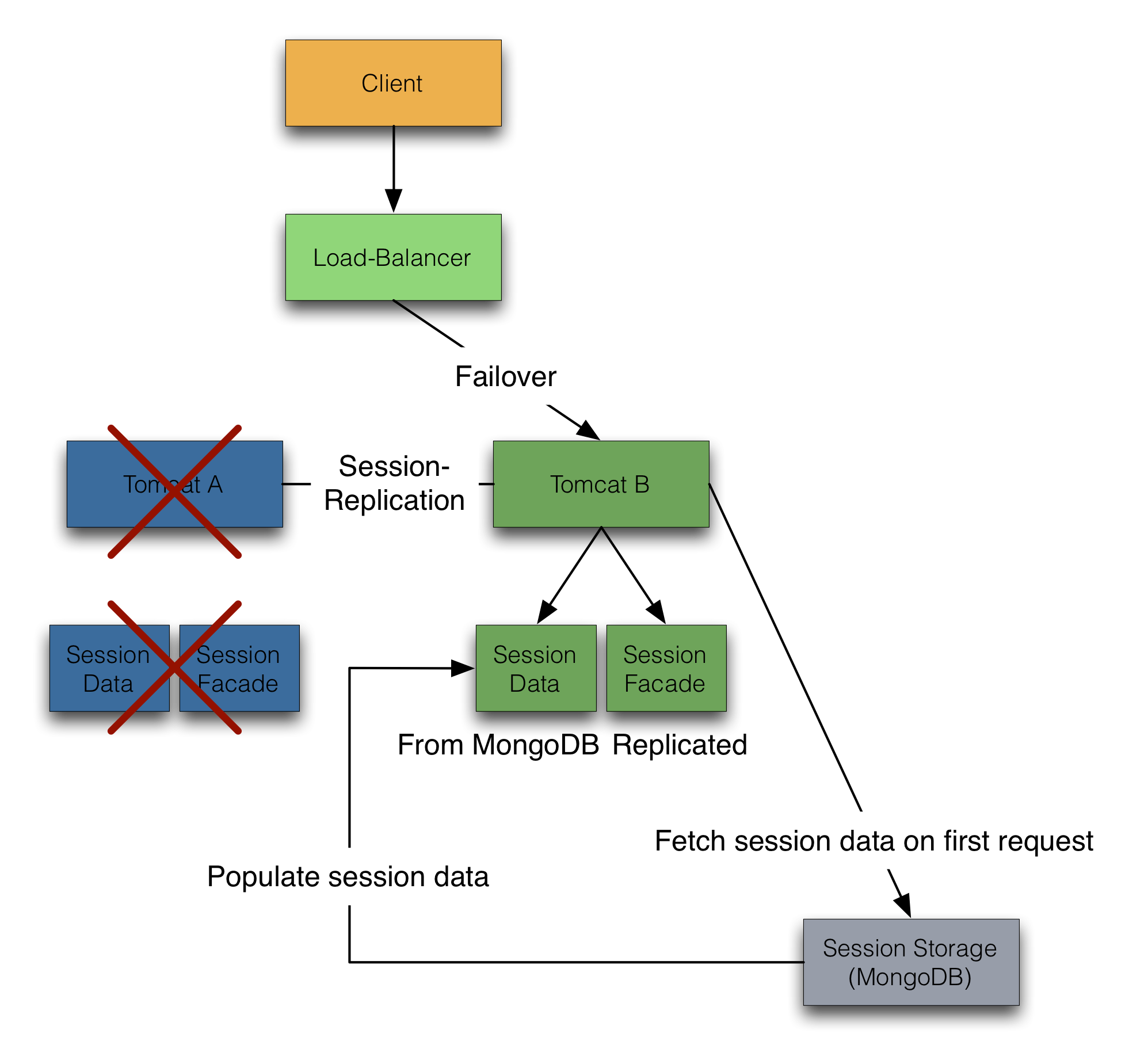
At a server failure (server holding the session) another server will receive the request (same as above). But now the server will check his local session timestamp against the global timestamp. If they differ, the server will pull the session data from the session store and recover the session state. Afterwards the server will serve the requests.
A server switch should be only a failover scenario. Sure, it would work as well for round-robin or by load/by requests distribution algorithms. In a local example the recovery overhead were some 2 or 3ms for a small session, but I wouldn't like that mode of operation. The regular execution time just incrementing a counter had some 4ms. A failover request (measured using Google's PageSpeed tools) took between 6 and 7ms. Pretty fast in my opinion.
Take a look at the code https://github.com/mp911de/distributed-web-sessions. The repo contains the source (built on Scala, Java, Akka and MongoDB with sbt) and an example config for Apache and two tomcats.