A slightly different approach is Branching by Abstraction. Branching by Abstraction causes you to wrap the functionality using one or more interfaces. So you create explicit boundaries, in case you didn’t do that already. Recently I had as well such a task.
There is an J2EE application, which consists of a bunch of EJB’s. These EJB’s are exposed directly using SOAP WebServices so some remote clients can connect to the application using SOAP. The problem hereby was, that the EJB’s were SOAP WebServices and other EJB’s were direct SOAP clients. A coupling of things which do not belong together: No Fault-Handling, no WebService model. And one day, there came EJBTransactionRolledback Exceptions as SOAP Fault. WTF?? Without any logging or handling no one knew, where they came from and what really goes on within the application.
This was the ideal starting point to branch by abstraction. Luckily, there are some defined EJB boundaries, which use a set of interfaces. So let’s exchange the services and consumers with real services and real clients. The application won’t notice anything, because it still uses interfaces.
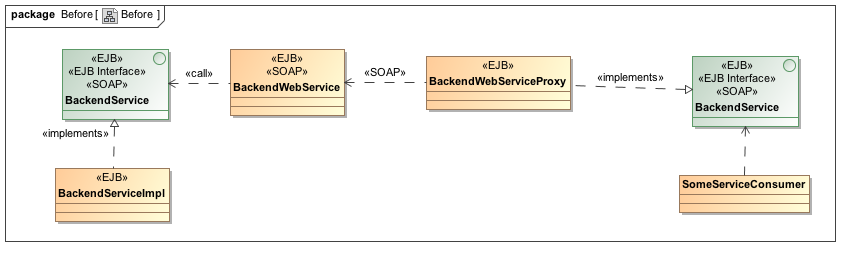
So the main idea here is, to create a new, dedicated SOAP Interface, new Service and Client classes. The Service classes itself are plain Java WebServices which use EJB’s (notice the difference between are EJB and use EJB!). On the other side, the clients are as well plain Java classes which access SOAP WebService addressing their interface. In the first shot we also wanted to fix the Exception/SOAP Fault mess we created earlier. This is now possible: Since the implementations, our client sees, are hidden by boundaries, we’re now free to do that. So the functionality of the Service and Client classes are no longer just delegate the call, but delegate the call and perform Exception-to-Fault conversion (in the Service) and Fault-to-Exception conversion (in the Client). The final picture looks like this:
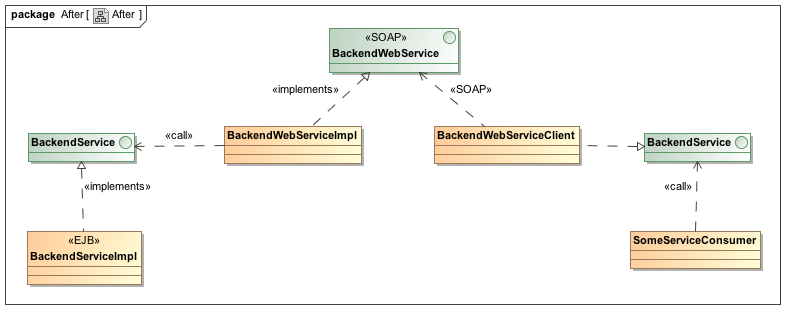
This branching allows me to do now everything behind the boundary. I can switch models, change exception handling and so on.
What about the test? I have lots of services and even more methods. I’m lazy, I don’t want to write hundreds of tests just for delegation. And you know what? I didn’t do that for every service. I wrote down the rules of behavior and created a general test for all services and clients together. How? Reflection!
See, for now the model used between the services is still the same (will change in the next iterations) and the methods are symmetric. Every method of the service boundary is contained within the WebService interface. In addition to the regular calls, exceptions are converted one to one. Every exception has it’s corresponding fault. This makes it easy to write a generic test which tests the happy path as well as all exception paths.
The rules are:
- Every call is delegated to either the backend service boundary or the WebService interface (without any model mapping)
- Every business fault is converted into a business exception and vice versa
- Every technical fault is converted in to a technical exception and vice versa
So my test just has to run over all the methods of the delegate and it’s wrapper (delegate WebService is called by the WebService client which is the wrapper and the backend service delegate is called by the WebService impl) and call the wrapper methods using some arguments. The arguments itself are either basic datatypes (strings, integers, booleans) or complex types (which can be mocked in a generic approach). On every wrapper invocation I expect a call to the delegate using the same arguments. In case of a method using return values I expect to receive the same return value which is returned by the delegate. This is the happy path. In the second iteration I’ll iterate over the declared exceptions of the delegate. Every exception, which is declared on the delegate must be handled. For business exceptions (faults) I expect a corresponding fault (exception). And finally technical, runtime exceptions. They have to be handled as well.
This approach produces 100% test coverage because I’ve specified my rules of behavior. The more tuples (WebService Client and WebService Interface, WebService Service and Business Interface), the more methods are test without any more effort. Take a look at my Gist https://gist.github.com/mp911de/6086572, there you'll find the Test itself and some snippets of the interfaces/services.
For this simple approach the tests are sufficient. It will get more complex as soon as the methods are not symmetric or different models are used for the transport layer. Then, again I’ll come to the point, where I’ve to write my tests for each unit.