parseFormatActor = context().actorOf(Props.create(ParseFormatActor.class), "parseFormatActor");
This snippet creates an actor, which is invoked in a singleton way. Multiple messages are processed in a sequential order.
parseFormatActor = context().actorOf(Props.create(ParseFormatActor.class).withRouter(new RoundRobinRouter(50)), "parseFormatActor");
And this one invokes the actor with up to 50 messages in parallel.
But how do you decide, which parts need to run in parallel and which run sequential? Is it about blocking? Is it IO?
In general, split your processing. If you have multiple steps within your processing, decouple them from each other.
In my scenario, I've a read from a file, a write to MongoDB and a write to Hadoop. In a traditional manner, every sequence would have to end in order to start over with the next file.
But that's not necessary. Files are read in one part and generate work for the MongoDB and Hadoop part. MongoDB writes are executed decoupled from the file read and the Hadoop writes. This means, I've not to wait any more until the Mongo writes are complete to start with the Hadoop writes or the next file. Since these backend systems are running on different services, they are not affecting each other. Every work stack is processed independent from the other.
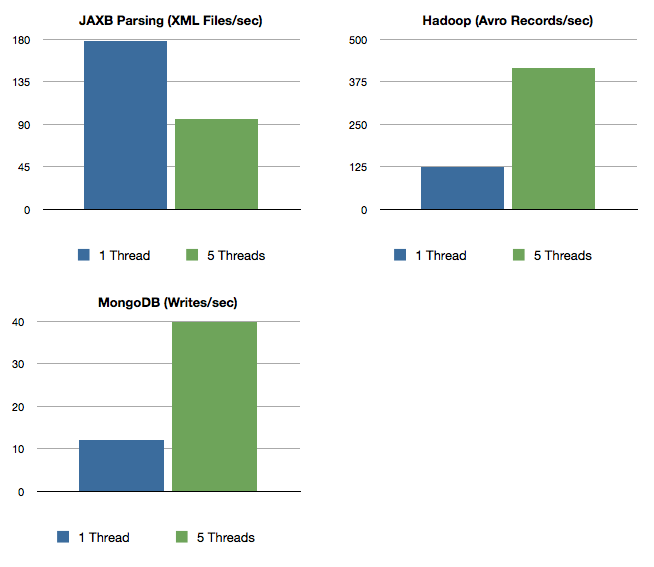
| Task | 1 Thread | 5 Threads |
|---|---|---|
| JAXB Parsing (XML Files/sec) | 178 | 95 |
| Hadoop (Writes Avro Records/sec) | 125 | 415 |
| MongoDB (Writes/sec) | 12 | 40 |
The table shows a small comparison on concurrency tuning. I've tested different scenarios on my environment to get the most out of the frameworks. The most important tool was a monitoring of the Akka mailboxes in order to find congestions. Second, you have to find the reason, why it's slow. On Hadoop, for example, I've had always a .work-File (which was a copy of the original file) and I created for each write new OutputStreams (and closed them afterwards). To optimize the write times, I eliminated the .work-File and keep the streams open until a sync/finish event is fired. This optimization changed average processing time from 1200msec to some 10-20msec.
It's very interesting, how concurrency affects software behavior.
Btw. my environment consists of a 3-node Hadoop cluster and a 4-node MongoDB cluster (2 shards, replicated on 2 machines) and a Mac (i7, SSD) running the Akka application.
You can find the code for Akka statistics on Github: https://github.com/mp911de/akka-actor-statistics